


今年,以ChatGPT为代表的新AI热潮奔涌而来,“大模型热潮”也从国外涌向了国内。
国产大模型“神仙打架”
AI大模型,指的是拥有数百万以上参数规模的深度神经网络模型。这类模型在经过专门的训练后,即可对海量数据进行复杂处理和任务处理。由OpenAI开发的ChatGPT之所以拥有强大的对话交互能力,背靠的正是名为“GPT”的AI预训练模型。
继百度文心一言之后,三六零、阿里、华为、京东、腾讯等大模型陆续浮出水面,国内AI大模型的追逐战正在愈演愈烈。
4月7日,阿里云公开“阿里版GPT”通义千问邀测入口,引发强烈关注。4月11日,阿里云再放大招——阿里巴巴所有产品未来将接入“通义千问”大模型。与百度于3月中旬上线的“文心一言”大模型工具类似,“通义千问”也具备与用户进行多轮对话的能力,并支持代码编程、文案创作等功能。
4月8日,在人工智能大模型技术高峰论坛上,华为云人工智能领域首席科学家田奇介绍了盘古大模型的进展及其应用状况。据介绍,该模型利用了深度学习与自然语言处理技术,并且采用海量中文语料库对其进行培训。
同日,京东也宣布将在今年发布“ChatJD”,定位为产业版本ChatGPT。目前京东的大模型主要聚焦于文本、语音、对话和数字人生成等4个方面开展工作,比如给商品自动生成长度不等的文案,包括标题、卖点文案和直播文案等。
4月9日,360宣布,将基于360GPT大模型开发人工智能产品矩阵“360智脑”,未来将其率先落地在“360搜索”场景,后续面向电商、营销、办公等场景深度落地。
4月10日,商汤科技公布“日日新SenseNova”大模型体系雏形,并现场演示了该模型体系下“商量SenseChat”语言工具的超长文本阅读理解、健康咨询等创新能力。
同日,游戏起家的昆仑万维也对外预告,不日将发布和奇点智源合作自研的大模型成果——“天工”3.5,并宣称这是“中国第一个真正实现智能涌现的国产大语言模型”。
4月11日,字节跳动旗下办公软件飞书发布视频,预告专属智能助手“My AI”,区别于其他大厂的AI智能工具,“My AI”似乎无意再复制一个类似ChatGPT的语言大模型,更类似微软推出的Office Copilot。
4月14日,腾讯云正式发布新一代HCC(High-Performance Computing Cluster)高性能计算集群。腾讯方面实测显示,腾讯云新一代集群的算力性能较前代提升高达3倍,是国内性能最强的大模型计算集群。
如今,包括百度、腾讯、阿里、华为、京东、360等多家国内科技巨头均已宣布在生成式AI产业有相应布局,5月,腾讯混元大模型也即将发布。
与此同时,大模型在学术界也成了“香饽饽”。早在今年2月,复旦大学邱锡鹏教授团队发布国内首个类ChatGPT模型MOSS。3月,中国人民大学卢志武团队自主研发多模态对话大模型并落地了第一款应用“元乘象ChatImg”……
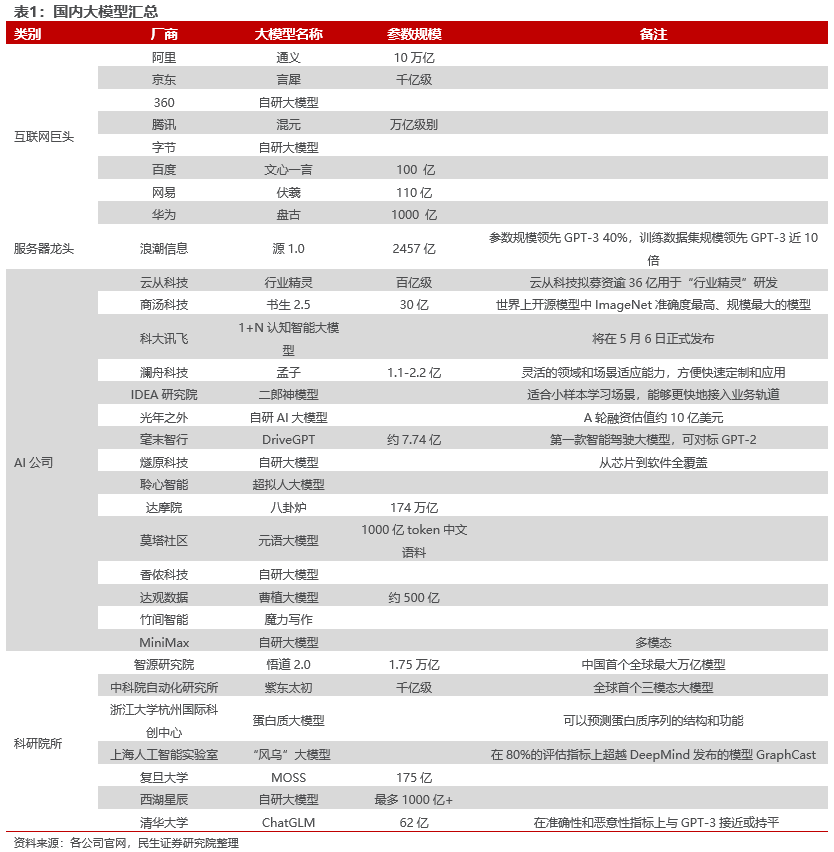
根据公开信息不完全统计,目前国内至少已经有30多家大模型亮相,其中不乏参数规模甚至超过ChatGPT规模的大模型,厂商涵盖了互联网巨头、AI上市公司、服务器龙头企业、科研院所与一级市场创业公司。
此外,随着ChatGPT的火爆,国内还火速兴起了AI大模型的创业风潮。
2023年2月,原美团联合创始人王慧文发布“AI英雄榜”,并火速启动A轮融资;随后,创新工场CEO李开复、前搜狗CEO王小川、前京东AI掌门人周伯文、出门问问创始人李志飞等掀起了AI大模型创业狂潮;阿里AI大牛贾扬清亦被爆出投身AI创业;还有一系列整合AI的新产品雨后春笋般涌现。
可以预计,在中国规模庞大的互联网用户的支撑下,国内企业在算法和算力上有望不断实现突破并取得领先。从算力到应用,已经按下了AI大模型发展的加速键。
国产大模型多为ToB
当前,国产大语言模型均未对公众大面积开放,也没有明确的ToC入口,未来发展大多也走ToB路线。
当前已正式上线的三家中,百度、商汤有关负责人曾向媒体表示,自家大模型为toB产品。阿里方面在4月11日举办的阿里云峰会上也宣称,未来“通义千问”将主要面对企业定制个性化服务。
而在已有消息的几家中,科大讯飞、网易有道两家皆已透露了基于公司类GPT技术所要落地的产品;京东的“ChatJD”明确定位为产业版本ChatGPT;而华为“盘古”系列下的NLP大模型主要面向智能文档搜索、智能ERP、小语种大模型等行业,多处理类案检索、企业财务异常检测等商业场景。
整体看来,国内大语言模型赛道的公司在开发模型后,更倾向于将相关模型嫁接到自家的C端服务中,或者走私有化部署、企业定制等路线。
而在与海外相同赛道的公司对比之后,不难得出第二个特点——相比海外,国内厂商更倾向于“每家必备”一个大模型。
当前,海外头部科技公司如OpenAI、谷歌等,其开发都以基础模型(Foundation Models)为主,不管是ChatGPT、Gpt4,还是PaLM-E,都是类似AI基础设施的基础大模型。其他公司,要么索性走开源社区的路线,要么像美国云服务巨头Salesforce一样,直接与OpenAI合作接入ChatGPT使用。在某种程度上,可以说是“大家都在规定范围里各自赚钱”。
谁是下一个OpenAI?
国内科技企业围绕AI大模型上演“百团大战”背后,谁能凭硬实力拔得头筹?
IDC中国助理研究总监卢言霞接受中新经纬采访时认为,当前各家公司密集发布大模型或公布大模型进展,主要还是被市场热度倒逼的。“事实上,行业成熟期远未到来,目前仍是起步阶段。但这种密集发布会推动大模型技术的落地,加速商业化。”卢言霞说。
中国电子商务专家服务中心副主任、知名互联网专家郭涛在接受证券日报采访时表示:“目前,国内AI大模型正处在从实验室走向大规模商业化的早期阶段,存在核心技术不成熟、成熟落地场景较少、生态系统不健全等突出问题。”深度科技研究院院长张孝荣也认为,国内AI大模型研发的水平还在实验室阶段,相关算法尚未成型。
浙江大学国际联合商学院数字经济与金融创新研究中心联席主任盘和林进一步介绍道,大模型生成式AI是弱智能向强智能的跨越,国内AI企业尚未跨越关键门槛。当前国内AI主要是中小模型,比如人脸识别,图像识别,简单语音对话,语义理解,应用范围很广,但在大模型应用方面,一方面海外更成熟的AI如今很难在国内落地,而国内又缺乏相关产品,所以还没有应用。
值得注意的是,在大模型“百花齐放”的当下,大多数公司看到的是机会,但也不排除有些公司是“炒概念”。对于投资者来说,还需要仔细甄别其中的风险。
民生证券研报认为,大模型表面不再稀缺后,实质格局更像“太极拳”:易学难精。因为开源基础以及大公司本身的算力储备与资金实力,单纯发布一个大模型门槛没有市场想象那么高。但是能够拥有高质量数据场景助力持续迭代,使得逐步性能逼近ChatGPT的大模型预计最终仍是“凤毛麟角”。市场会逐步凝结共识:得数据者得天下,数据是差异化竞争关键。
多国“围剿”ChatGPT,我国也出手监管AI
从国外AI大模型发展逻辑来看,当AI强大到一定地步,如GPT-4时,监管就显得很有必要。
当地时间3月31日,意大利个人数据保护局宣布,从即日起禁止使用聊天机器人ChatGPT,并限制开发这一平台的OpenAI公司处理意大利用户信息。
随后,4月3日,德国联邦数据保护专员Ulrich Kelber表示,德国可能会效仿意大利,以数据安全方面的担忧为由,屏蔽ChatGPT。
法国和爱尔兰方面也联系了意大利数据监管机构,并讨论了调查结果,同时,加拿大隐私专员办公室(OPC)宣布开始调查ChatGPT背后的公司OpenAI,涉及“指控OpenAI未经同意收集、使用和披露个人信息”等投诉。
不仅如此,多国企业和机构也开始调查或采取措施限制使用该软件。
3月末,韩国三星半导体部门发生了3起因员工在ChatGPT上输入设备信息及重要会议摘要,导致公司机密外泄风险陡增的事件。
台积电、软银、日立、富士通、日本瑞穗金融集团等企业也开始限制ChatGPT等交互式人工智能服务在商业运作中的使用。
此外,摩根大通已经限制员工使用ChatGPT,亚马逊、微软和沃尔玛也已向员工发出警告,要求员工谨慎使用生成式AI服务,埃森哲则警告员工不要将客户信息暴露在ChatGPT中。
与此同时,另一个引发关注的焦点是,如今GPT-4可能具备“自我进化”的能力。前谷歌大脑研究工程师Eric Jang发现,GPT-4能够以合理的方式批评自己的成果,“AI是否能够超越人类”这个终极难题再度浮现。
曾有微软研究员发推说GPT-4根本无法写出“不押韵”的诗歌。然而,当再去询问GPT-4是否完成了任务。这时,它道歉后,生成了一个不押韵的诗,可以说是满分。
似乎,人工智能发展到现在,已经成为令人“不安”的存在。
国内方面,国家互联网信息办公室就《生成式人工智能服务管理办法(征求意见稿)》(简称《征求意见稿》)公开征求意见,《征求意见稿》共21条,从生成式人工智能服务商的准入,到算法设计、训练数据选择、模型到内容,以及用户实名和个人隐私、商业秘密等方面提出了相关要求。这意味着,当下爆火的生成式AI产业将迎来首份监管文件。
其中管理办法涉及的生成式人工智能包括基于算法、模型、规则生成文本、图片、声音、视频、代码等内容的技术。并对利用生成式人工智能产品提供聊天和文本、图像、声音生成等服务的组织和个人(简称“提供者”)的责任进行了规定。
对于生成式人工智能产品,提供者需要按照《互联网信息服务深度合成管理规定》对生成的图片、视频等内容进行标识等。
在合理的控制下,大模型成为AI时代的基础设施已是可以预见的事。在日趋激烈的国产AI赛道上,谁能更好地把控算法、算力、数据、产品、场景这五个维度,谁就能获得更多的可能性。